4 دلیل برای علامتگذاری متن به عنوان محتوای هوش مصنوعی
ابزارهای تشخیص محتوای هوش مصنوعی، اغلب بر اساس الگوهای مشخصی کار میکنند که در مدلهای زبانی بزرگ دیده میشود. این ابزارها به ویژگیهایی مانند ساختار جمله، تکرار عبارات خاص یا حتی سطح رسمی بودن متن حساس هستند. با توجه به تنوع و پیچیدگی سبک نوشتار انسانی که شامل خلاقیت، نوآوریهای زبانی و حتی اشتباهات طبیعی میشود، این ابزارها ممکن است بهاشتباه، محتوای تولید شده توسط انسان را به عنوان خروجی یک مدل زبانی بزرگ شناسایی کنند. بدون حذف هیچ بخش از متن، میتوانید با بهبود ساختار جملهها و ایجاد تنوع در انتخاب کلمات، احتمال این تشخیص اشتباه را کاهش دهید.
ابزارهای تولید محتوای هوش مصنوعی، دنیای محتوا را به شکل چشمگیری متحول کردهاند. این ابزارها با قابلیتهای متنوعی که به کاربران ارائه میدهند، به آنها کمک میکنند تا محتوای باکیفیت و بهینهای را در کمترین زمان ممکن تولید کنند. امروزه، کاربرد هوش مصنوعی به مراتب بیشتر قبل شده و تولید کنندگان محتوای وبسایت و نویسندگان، از هوش مصنوعی برای پیشبرد اهداف، کاهش هزینه و صرفهجویی در زمان استفاده میکنند.
انواع محتوای نوشتاری هوش مصنوعی به طور کلی به دو دسته محتوای کوتاه و بلند تقسیم میشوند. محتوای کوتاه شامل تولید عنوان، توضیحات کوتاه، پستهای شبکههای اجتماعی، ایمیلهای کوتاه و سایر موارد است. در مقابل، محتوای بلند شامل تولید مقالات، گزارشها، کتابهای الکترونیکی، فیلمنامه و غیره است.
برخی از کاربردهای رایج محتوای متنی هوش مصنوعی عبارتند از:
- تولید محتوا برای وبلاگها و سایتها: از تولید ایده برای پستهای وبلاگ گرفته تا نوشتن مقالات کامل
- ایجاد محتوا برای بازاریابی: تولید متن تبلیغاتی، ایمیلهای بازاریابی، پستهای شبکههای اجتماعی و غیره.
- تولید محتوا برای آموزش: ایجاد مطالب آموزشی، آزمونها و تمرینها
- تولید محتوا برای سرگرمی: نوشتن داستانهای کوتاه، شعر و فیلمنامه
ابزارهای تولید محتوای متنی چگونه کار میکنند؟

اگر در گوگل بهدنبال ابزارهای تولید محتوای متنی بگردید، متوجه خواهید شد که دهها گزینه اختصاصی مختلف وجود دارد که تقریباً ویژگیهای مشابهی دارند. دلیل اصلی این موضوع این است که 95٪ از این ابزارها از همان مدلهای زبانی بزرگ (LLM) بهعنوان هسته اصلی یا مغز متفکر بهره میبرند. اکثر آنها فقط رابطهایی برای OpenAI و Claude API هستند که چند ویژگی اضافی به آنها اضافه شده است. با اینکه بعضی از کاربران از تفاوتهای بین ابزارهای اصلی و شخص ثالث آگاه نیستند و شرکتها برای تبلیغات و بازاریابی، از رازها پرده بر نمیدارند، اما شباهتهای محسوسی بین آنها وجود دارد که با مقایسه عملکرد، خواهید فهمید.
با کمی راهنمایی، میتوانید نتایج مشابهی از ChatGPT و Gemini را دریافت کنید که از همان مدلهای زبانی بزرگ بهعنوان چتبات استفاده میکنند. اگر بخواهید، حتی میتوانید ابزار تولید محتوای متنی خود را بدون نیاز به کدنویسی و با ادغام OpenAI در Zapier بسازید.
براساس دلایل ذکر شده، برنامههایی مانند Microsoft Word، Google Docs، Notion و Coda ابزارهای تولید محتوای هوش مصنوعی را به سرعت به سرویس خود اضافه کردند. چنین برنامههایی به ایجاد یک مدل زبانی بزرگ جدید نیازی ندارند و فقط باید یکی از مدلهای اصلی را بکار بگیرند (یا از LLM که محصول سالها تحقیق و توسعه پیشرفته آزمایشگاههای آنها (مانند گوگل) است، استفاده کنند.)
مدلهای زبانی پایه (Foundation Language Models یا FLLM) در واقع مغز متفکر بسیاری از سیستمهای هوش مصنوعی هستند که با زبان سر و کار دارند. این مدلها بر پایه شبکههای عصبی بسیار بزرگ طراحی شدهاند و با آموزش دیدن از طریق حجم عظیمی از دادههای متنی، توانایی درک و تولید و پردازش زبان طبیعی را کسب میکنند. این مدلها با تحلیل الگوها و روابط بین کلمات و جملات، درک عمیقی از ساختار و معنای زبان پیدا میکنند. به عبارت سادهتر، آنها یاد میگیرند که کلمات چگونه با هم ترکیب میشوند تا جملات معنادار بسازند و این جملات چگونه میتوانند در متنون بزرگتر به کار بروند.
دادههای آموزشی شامل کتابها، مقالات و دیگر اسناد در موضوعات، سبکها و ژانرهای مختلف هستند و بخش عظیمی از محتوای جمعآوریشده نیز از اینترنت نشات میگیرد. به عبارت دیگر، LLMها میتوانند به مجموعهی گستردهای از دانش بشری دسترسی داشته باشند و با استفاده از این دادهها، یک شبکه عصبی یادگیری عمیق پیچیده و چندلایه را آموزش بدهند؛ الگوریتمی که به عنوان مدل سادهسازی شدهای از مغز انسان عمل میکند. این رویکرد، اگرچه برای ایجاد برنامههایی با قابلیت تولید متن خلاقانه و متنوع ضروری است، اما به تنهایی نمیتواند تضمینکننده محتوای باکیفیت باشد. برای تولید شعرهایی با ارزش ادبی، عوامل دیگری مانند درک عمیق از زیباییشناسی شعر، دانش ادبیات و توانایی ترکیب خلاقانه مفاهیم مختلف نیز ضروری هستند.

اگر میخواهید بیشتر وارد جزئیات شوید، میتوانید مقالات Zapier در مورد پردازش زبان طبیعی و نحوه عملکرد ChatGPT را مطالعه کنید، اما بهطور کلی، باید به این موضوع اشاره کرد که مدلهای زبانی بزرگ مانند GPT و دیگر مدلهای مشابه، به شکل انکارناپذیری توسعه یافتهاند و مهارت آنها در نگارش متون و گردآوری دادهها موجب شده تا در زمینه تولید محتوای متنی کاربرد داشته باشند.
چگونه از ابزارهای تولید محتوای متنی استفاده کنیم؟
یکی از نگرانیهای اولیه که با هجوم ابزارهای تولید محتوای هوش مصنوعی مطرح شد، این بود که دانشجویان از آن برای نوشتن مقالههای خود استفاده میکردند یا افراد حرفهای، وظایف کاری خود در حوزه نویسندگی را به هوش مصنوعی میسپردند و از مسئولیت خود شانه خالی میکردند.
با این حال، هوش مصنوعی میتواند بهعنوان ابزاری مفید مورد استفاده قرار گیرد. هر کاربر میتواند از یک چتبات برای انجام کارهایی نظیر تحقیق، ایدهپردازی و سازماندهی وظایف استفاده کند. اگر تصور میکنید که هوش مصنوعی نمیتواند به درستی، متون مورد نظر شما را نگارش کند و یا با سیستم نگارش زبان فارسی آشنا نیست، میتوانید وظیفه جمعآوری اطلاعات را به او بسپارید و سپس از طریق همان منابع، محتوای مورد نظر خود را آماده کنید. یکی از ویژگیهای کلیدی چتباتها، یاد گرفتن است. از اینرو، میتوانید از طریق پرامپت نویسی، محتوای مطلوبی تولید کنید و سپس از طریق ویرایش، آن را برای مخاطبین آماده کنید.
در ادامه، قصد داریم تا به معرفی عواملی بپردازیم، که باعث میشوند تا ابزارهای تشخیص محتوای هوش مصنوعی، متون شما را نیز به هوش مصنوعی ربط دهند. علاوهبراین، به معرفی راهکارها برای حل این مشکل نیز خواهیم پرداخت.
1. گرامر متن شما بینقص است
یکی از روشهایی که ابزارهای شناسایی هوش مصنوعی برای تشخیص متون تولیدشده توسط هوش مصنوعی استفاده میکنند، بررسی میزان دقت در گرامر و همچنین استفاده از ساختارهای استاندارد یا رایج جملات است. بهطور تئوری، هوش مصنوعی مرتکب اشتباهات گرامری نمیشود، اما حتی بهترین نویسندگان نیز ممکن است هنگام نوشتن دچار اشتباهات جزئی شوند. به همین ترتیب، اگر نوشتههای شما فاقد ریسک باشند و از نظر گرامری بیش از حد عمومی و بیروح به نظر برسند، این موضوع میتواند تاثیر بسزایی در سبک نوشتاری شما ایجاد کند و آن را به هوش مصنوعی، نزدیکتر کند.
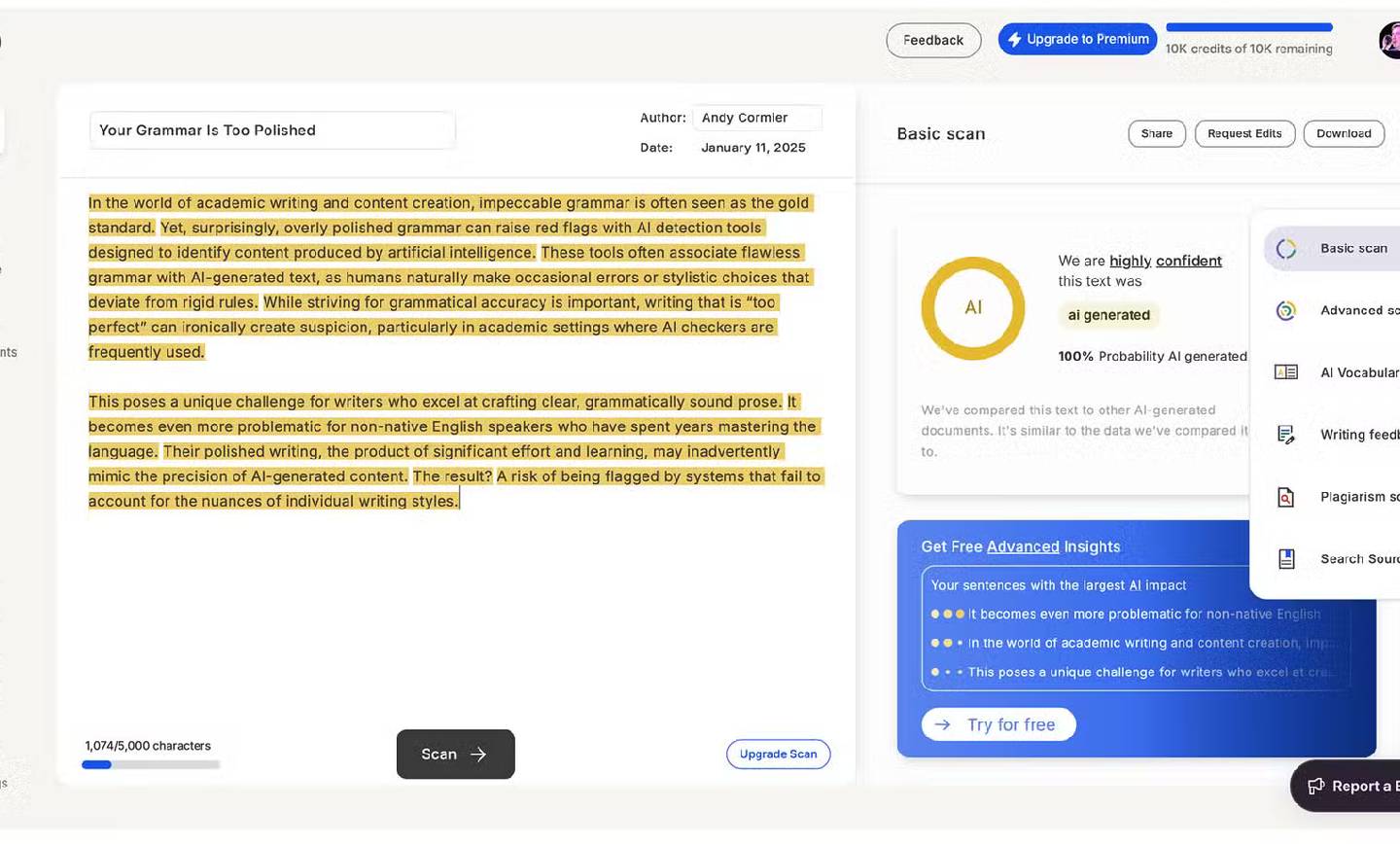
تشخیص دقیق GPTZero مبنی بر اینکه متن مورد نظر با احتمال ۱۰۰% توسط هوش مصنوعی تولید شده، نشاندهنده الگوهای زبانی مشخص و قابل تشخیص در متن است که شباهت زیادی به خروجیهای معمول مدلهای زبانی بزرگ دارد.
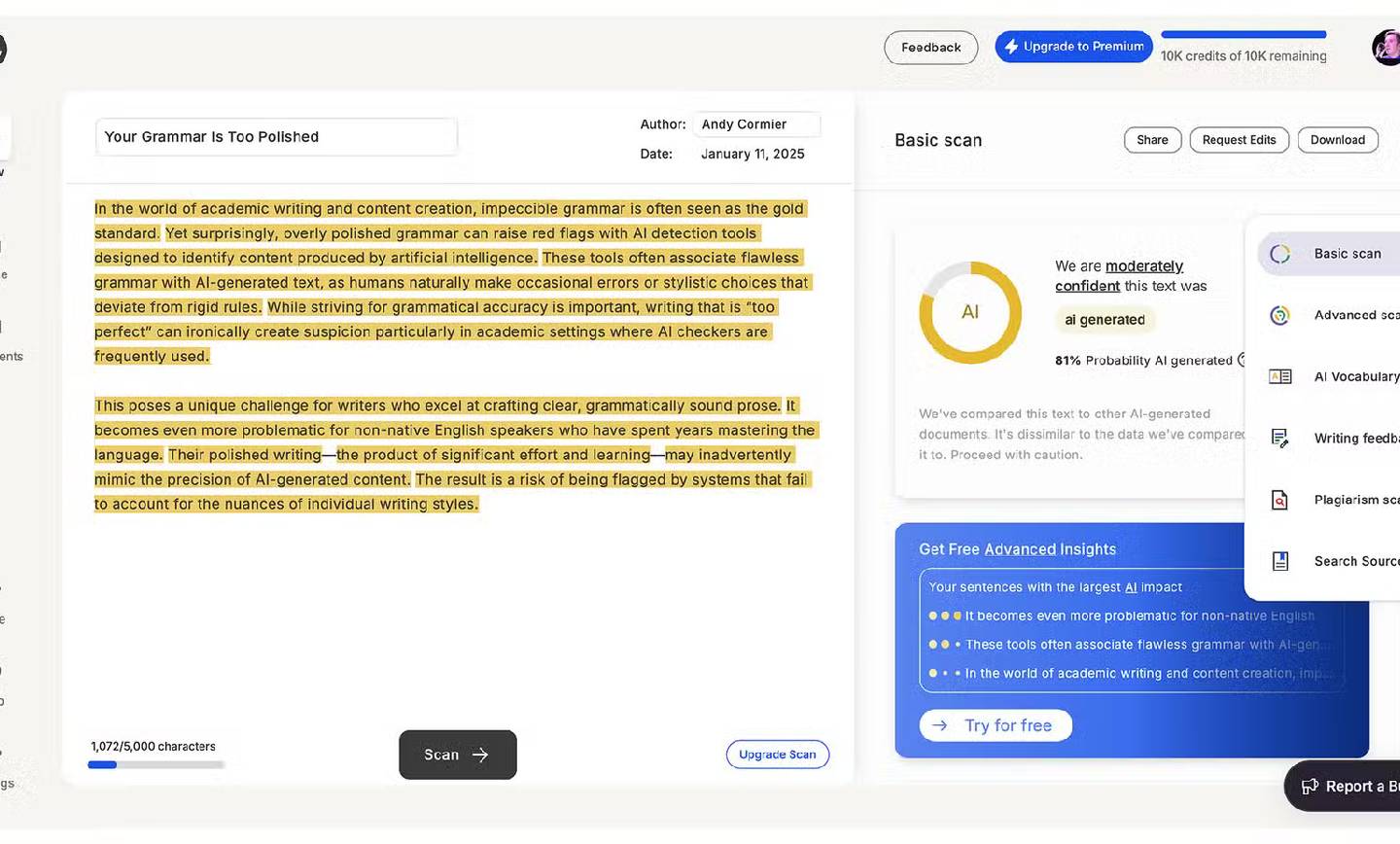
اگر چند اشتباه کوچک گرامری، مانند حذف چند کاما و اضافه کردن یک اشتباه تایپی، همراه با چند تغییر کوچک در نوشته ایجاد کنیم، امتیاز GPTZero بهطور قابلتوجهی کاهش پیدا میکند و به ۸۱٪ میرسد.
2. استفاده از کلمات رایج و معمولی
هنگام مطالعه یک متن، اغلب به طور غریزی احساس میکنیم که آیا این متن توسط هوش مصنوعی تولید شده است یا نه. این حس معمولا از ویژگیهایی مانند ساختار نامنظم پاراگرافها و تکرار بیش از حد برخی واژهها و عبارتهای مشخص دیگر نشأت میگیرد. این پدیده به ویژه پس از ظهور ChatGPT در سال ۲۰۲2 و افزایش چشمگیر استفاده از کلمه “delve” در مقالات پژوهشی، به وضوح قابل مشاهده شد. این عوامل نشان میدهد که الگوهای زبانی مشخصی وجود دارند که میتوان از آنها برای تشخیص متون تولید شده توسط هوش مصنوعی استفاده کرد.
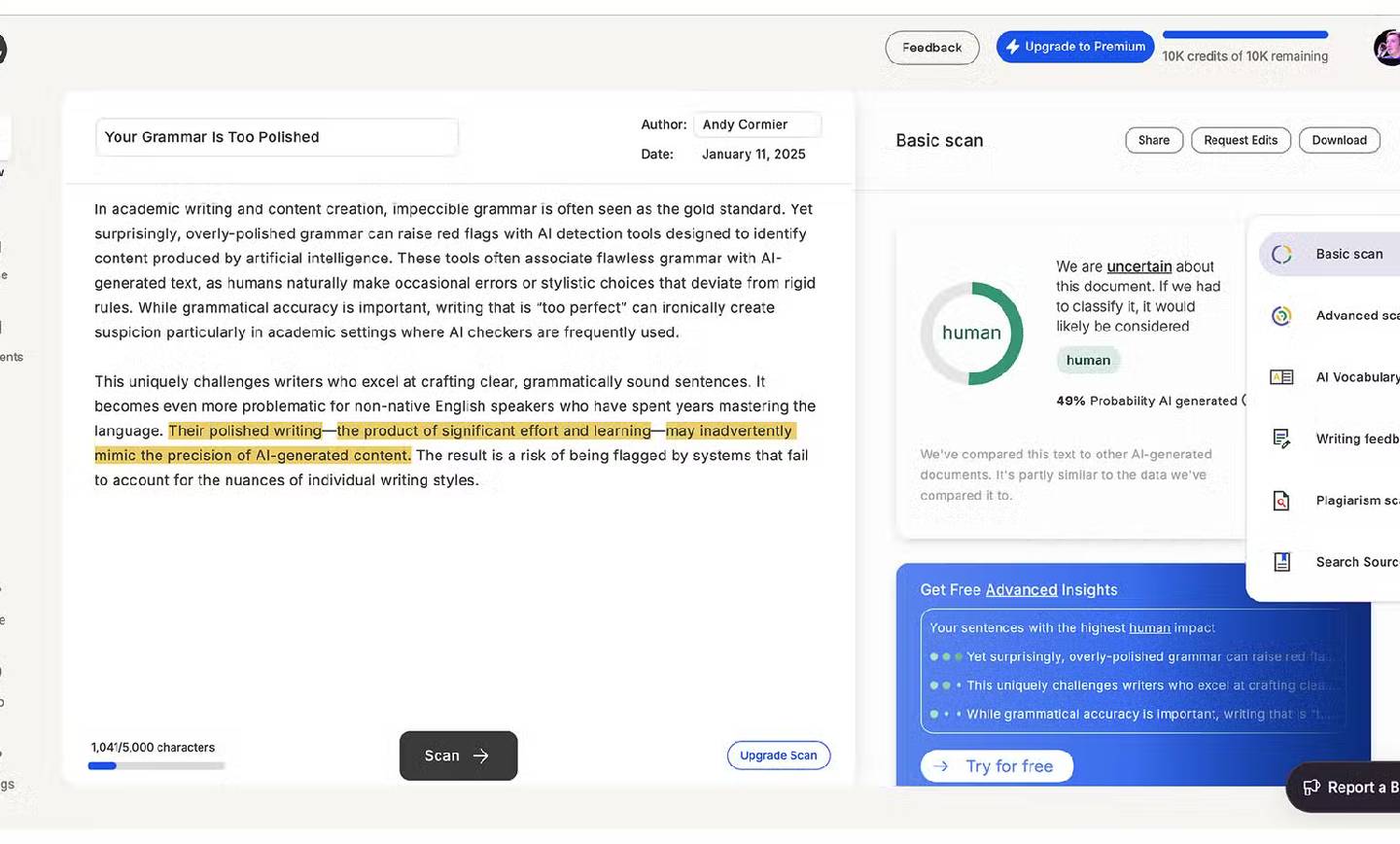
با اعمال چند تغییر جزئی در بخشهایی که معمولاً بهعنوان نشانههای بارز متن تولیدشده توسط هوش مصنوعی شناسایی میشوند، امتیاز متن در ابزار GPTZero به طور قابل توجهی کاهش یافت و به ۴۹٪ رسید؛ امتیازی که نشاندهنده ماهیت انسانی متن است. با این حال، در محیطهای آکادمیک که دقت بسیار بالایی مورد نیاز است، حتی چنین امتیازی ممکن است شک برانگیز باشد. این مثال به وضوح نشان میدهد که ابزارهای تشخیص محتوای هوش مصنوعی با وجود پیشرفتهای اخیر، همچنان نسبت به تغییرات جزئی حساس هستند و به راحتی فریب میخورند. این موضوع نگرانیهایی را در مورد قابلیت اطمینان این ابزارها و محدودیتهای آنها در تشخیص دقیق متون تولید شده توسط هوش مصنوعی ایجاد میکند.
نویسنده وبسایت MUO در رابطه با این موضوع گفت:
من سالهاست که به دانشجویان غیر بومی زبان انگلیسی، نگارش انگلیسی درس میدهم و خیلی از این دانشجوها از من شکایت میکنند که ابزارهای تشخیص محتوای هوش مصنوعی، اغلب اوقات اشتباه میکنند و میگویند که نوشتههای آنها توسط کامپیوتر نوشته شده است.
دلیل این مشکل این است که وقتی میخواهیم به کامپیوتر یاد بدهیم که مثل انسان بنویسد، از آدمهای زیادی میخواهیم که به متنهای مختلف برچسب بزنند و بگویند که این متن توسط انسان نوشته شده یا کامپیوتر. با اینحال، خیلی از افرادی که این کار را میکنند، انگلیسی زبان مادریشان نیست. مثلاً ممکن است کلمهای مثل “delve” (که یعنی عمیق شدن در چیزی) را زیاد استفاده کنند، چون این کلمه در زبان خودشان هم معادل مشابه دارد. به همین دلیل، کامپیوتر یاد میگیرد که وقتی کلمه “delve” را میبیند، فکر کند که این متن توسط یک آدم غیربومی زبان انگلیسی نوشته شده است.
نکته قابل توجه دیگری که این مسئله را پیچیدهتر میکند، تسلط بیشتر زبانآموزان غیربومی بر قواعد دستوری زبان انگلیسی نسبت به بسیاری از افراد بومیزبان است. این زبانآموزان اغلب به دلیل رعایت دقیق دستور زبان و انتخاب واژگان مناسب، نوشتههایی بسیار ساختار یافتهتر و رسمی تولید میکنند. در نتیجه، ابزارهای تشخیص هوش مصنوعی ممکن است به اشتباه، نوشتههای این افراد را به عنوان متون تولید شده توسط هوش مصنوعی شناسایی کنند و این موضوع، ناعادلانهبودن این ابزارها را در قبال زبانآموزان غیربومی آشکار میکند.
3. استفاده از ابزارهای نویسندگی

مشکلاتی که تاکنون به آنها اشاره شد، حتی بدون استفاده از ابزارهای تولید محتوای مبتنی بر هوش مصنوعی نیز قابل مشاهده است. برای مثال، اگر نویسندهای تلاش کند تا متنی اصیل تولید کند و در عین حال از ابزارهای ویرایشی مانند Grammarly استفاده کند، احتمال تشخیص آن به عنوان محتوای تولید شده توسط هوش مصنوعی افزایش مییابد. این امر به ویژه در محیطهای آکادمیک حائز اهمیت است، زیرا این ابزارها به نوعی دستیارهای نوشتاری هوش مصنوعی محسوب میشوند و دانشجویان ممکن است به جای یادگیری مهارتهای نوشتن، به آنها اتکا کنند. این مساله یک منطقه خاکستری را ایجاد میکند که در آن مرز بین استفاده مجاز از ابزارهای کمکی و تکیه بیش از حد بر آنها مبهم است.
تجربه نشان میدهد که وابستگی بیش از حد دانشجویان به ابزارهایی مانند Grammarly برای بهبود نوشتار، منجر به نگرانی آنها در مورد تشخیص نوشتههایشان به عنوان محتوای تولید شده توسط هوش مصنوعی میشود. زمانی که بخش قابل توجهی از یک متن بر اساس پیشنهادات این ابزارها بازنویسی شود، در واقع بخش قابل توجهی از آن توسط هوش مصنوعی تولید شده است. بنابراین، استفاده از این ابزارها باید با احتیاط همراه باشد. به جای اتکا و صرف زمان برای پیشنهادات، بهتر است از آنها به عنوان راهنمایی برای بهبود مهارتهای نوشتاری استفاده کرد. به این ترتیب، میتوانیم بدون اینکه اصالت و کیفیت کارمان زیر سوال برود از مزایای این ابزارها بهرهمند شویم.
4. کپی کردن از چتبات

اگر به طور کامل به خروجی ChatGPT متکی باشید و متون مورد نظر خود را ویرایش نکنید، ابزارهای تشخیص هوش مصنوعی به راحتی متوجه این موضوع خواهند شد و این یک تشخیص اشتباه نخواهد بود. از سوی دیگر، حتی اگر با صرف زمان و تلاش بسیار سعی کنید متنی کاملا اصیل و شخصی بنویسید، استفاده از گرامر دقیق و انتخاب واژگان خاص ممکن است باعث شود که نوشته شما به اشتباه به عنوان محصول یک هوش مصنوعی شناخته شود. این تناقض نشان میدهد که ابزارهای تشخیص هوش مصنوعی، با وجود پیشرفتهایشان، هنوز هم با چالشهای جدی در تشخیص دقیق بین محتوای تولید شده توسط انسان و هوش مصنوعی روبرو هستند.
این مسئله به وضوح نشان میدهد که ابزارهای تشخیص محتوای هوش مصنوعی، با وجود پیشرفتهای چشمگیر، هنوز محدودیتهای جدی روبرو هستند. این ابزارها نمیتوانند جایگزین قضاوت و ارزیابی انسانی شوند و ممکن است به طور ناعادلانهای به نویسندگان، بهخصوص کسانی که به زبان انگلیسی بهعنوان زبان دوم تسلط دارند، ظلم کنند.
در حالی که ابزارهای هوش مصنوعی میتوانند به عنوان دستیارانی قدرتمند برای نویسندگان مورد استفاده قرار بگیرند و روند تولید محتوا را تسریع بخشند، اما نمیتوانند جایگزین خلاقیت، نوآوری و درک عمیق انسان از موضوعات شوند. بهترین رویکرد برای تولید محتوای باکیفیت، تلفیق هوشمندانه تواناییهای هوش مصنوعی و خلاقیت انسان است. به این ترتیب، میتوانیم از مزایای هر دو بهرهمند شده و محتوایی جذاب، اصیل و متناسب با نیازهای مخاطبان تولید کنیم.
منبع: MUO